Całkowicie nowe narzędzie umożliwiające szybkie przekazywanie w NAZCA danych pochodzących ze źródeł, do narzędzi służących ich archiwizacji, bez udziału logiki systemu. Aktualnie narzędzie to służy do przekazywania danych z pinów wyjściowych węzłów do serwera Kafka.
W celu korzystania z Globalnych archiwizatorów konieczne jest skonfigurowanie serwera Kafka w Topologii. Obecnie dodano możliwość podawania wielu tematów, pod warunkiem oddzielenia ich średnikami. Narzędzie obsługuje trzy mechanizmy:
1. Sekcje
2. Grupy zdarzeń
3. Obiekty wiedzy
Sekcje
Każda sekcja musi posiadać nazwę, adresata (serwer Kafka) oraz interwał (podawany w milisekundach). Interwał to odstęp czasowy, po którym wysyłane będą dane do serwera Kafka.
W przypadku braku dostępności serwera Kafka wszystkie dane zapisywane są do plików .csv i wysyłane do serwera Kafka po odzyskaniu połączenia.
Ustalono limit 10 sekcji.
Moduły
Do każdej sekcji można dodać jeden lub więcej modułów. Moduły wczytywane są z plików .iodd zawierających informacje o module i parametrach danego modułu.
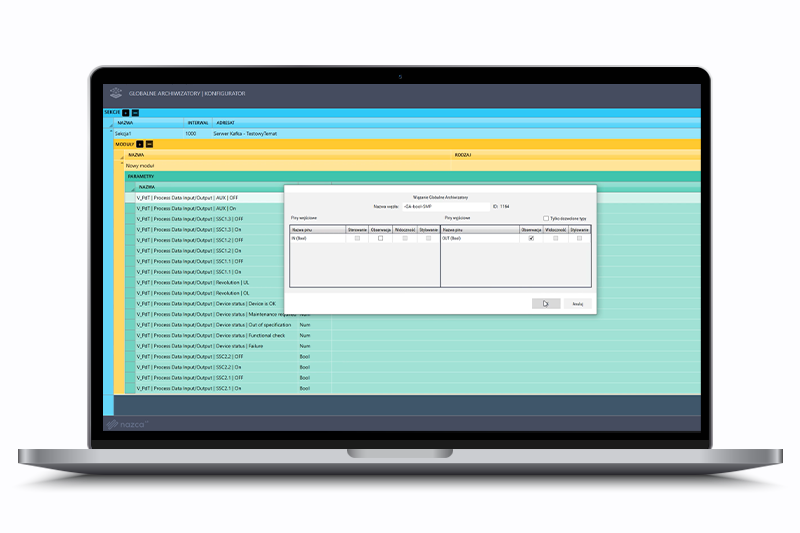
Parametry
Wczytanym z pliku parametrom można dowiązać piny wyjściowe odpowiednie dla typu parametru. Dane z tych pinów, co ustalony interwał, będą wysyłane do serwera Kafka (wysyłane będą informacje wyłącznie o tych parametrach, które mają powiązanie z pinem).
Grupy zdarzeń
Każda grupa zdarzeń musi posiadać nazwę i adresata (serwer Kafka). Do każdej grupy zdarzeń można z pliku .iodd wczytać zdarzenia, a następnie powiązać je z wyjściowymi pinami typu bool. Informacje zostaną wysłane do serwera Kafka w momencie zmiany wartości na powiązanym pinie.
Obiekty wiedzy
Każdy obiekt wiedzy musi posiadać nazwę i adresata (serwer Kafka). Do każdego obiektu wiedzy możliwe jest dodanie jednostek wiedzy.
Jednostki wiedzy
Jednostka wiedzy składa się z klucza, nazwy oraz wartości. Każda z tych własności posiada wiązanie z pinem wyjściowym.
Mechanizm globalnych archiwizatorów